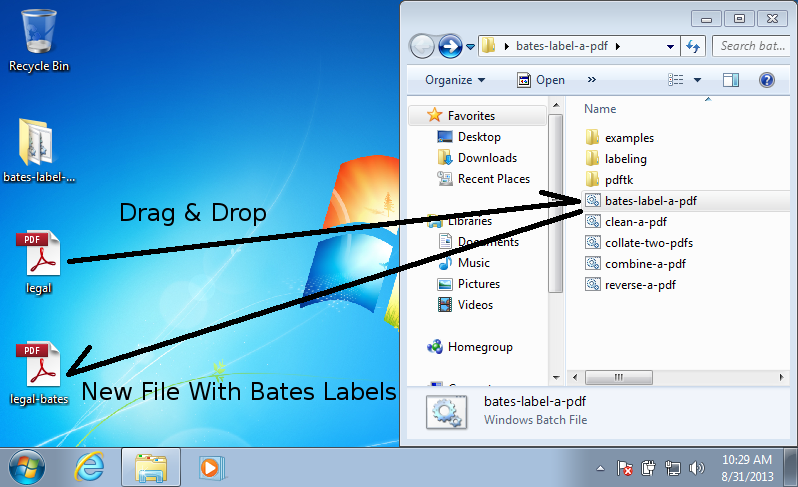
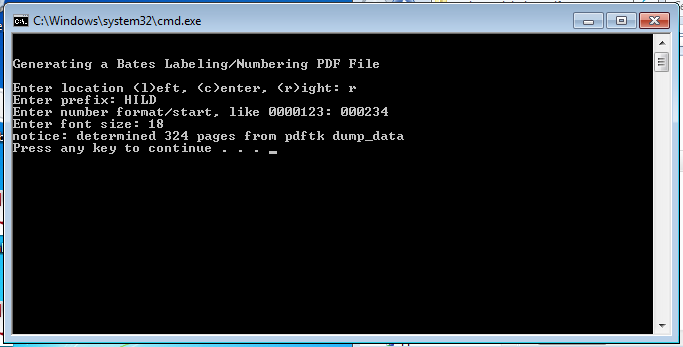
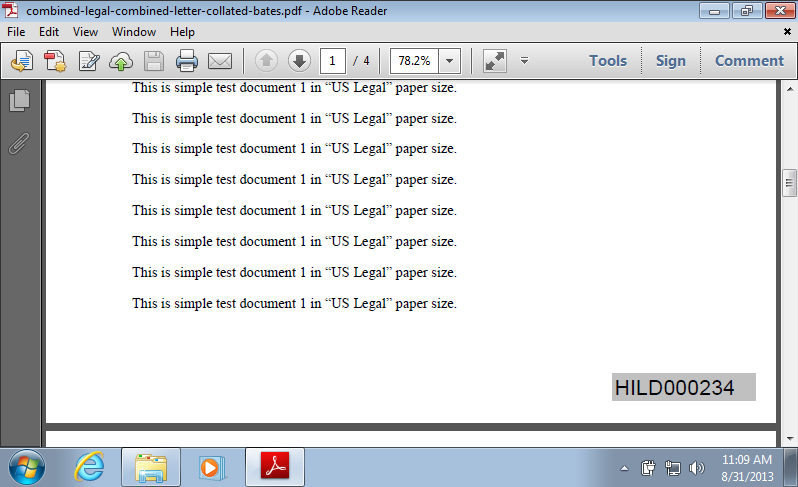
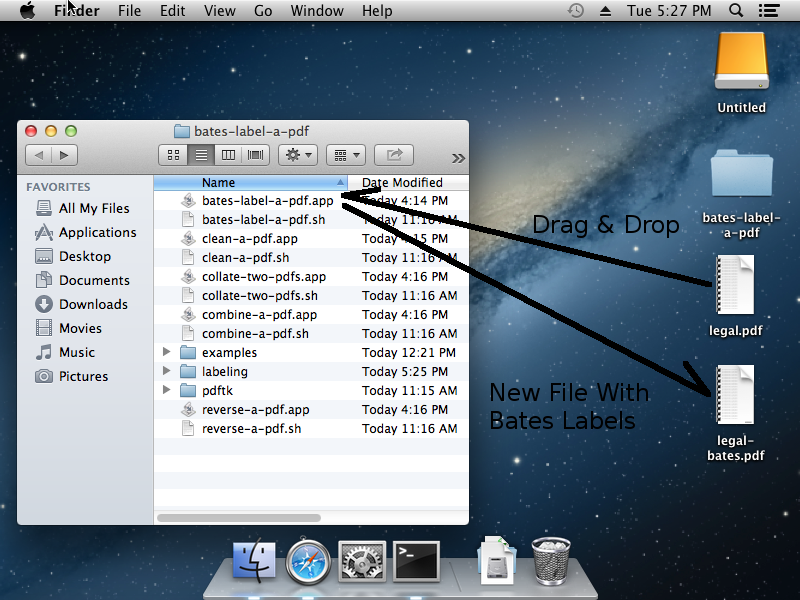
for FILE in test_files/*.pdf; do
time ./bates-label-a-pdf.sh $FILE
done
| pages | MB | seconds | pages per second | |
|---|---|---|---|---|
| legal1.pdf (included) | 1 | 0.06 | 1.739 | 0.575 |
| lessons_in_electric_circuits_ac.pdf | 528 | 3.88 | 2.277 | 231.884 |
| lessons_in_electric_circuits_dc.pdf | 530 | 4.36 | 2.229 | 237.775 |
| linux_device_drivers.pdf | 632 | 12.88 | 2.372 | 266.442 |
| light and matter.pdf | 1020 | 83.02 | 2.989 | 341.251 |
| light and matter x10.pdf | 10200 | 830.11 | 28.278 | 360.704 |